https://github.com/krillinai/KrillinAI
1. 应用配置
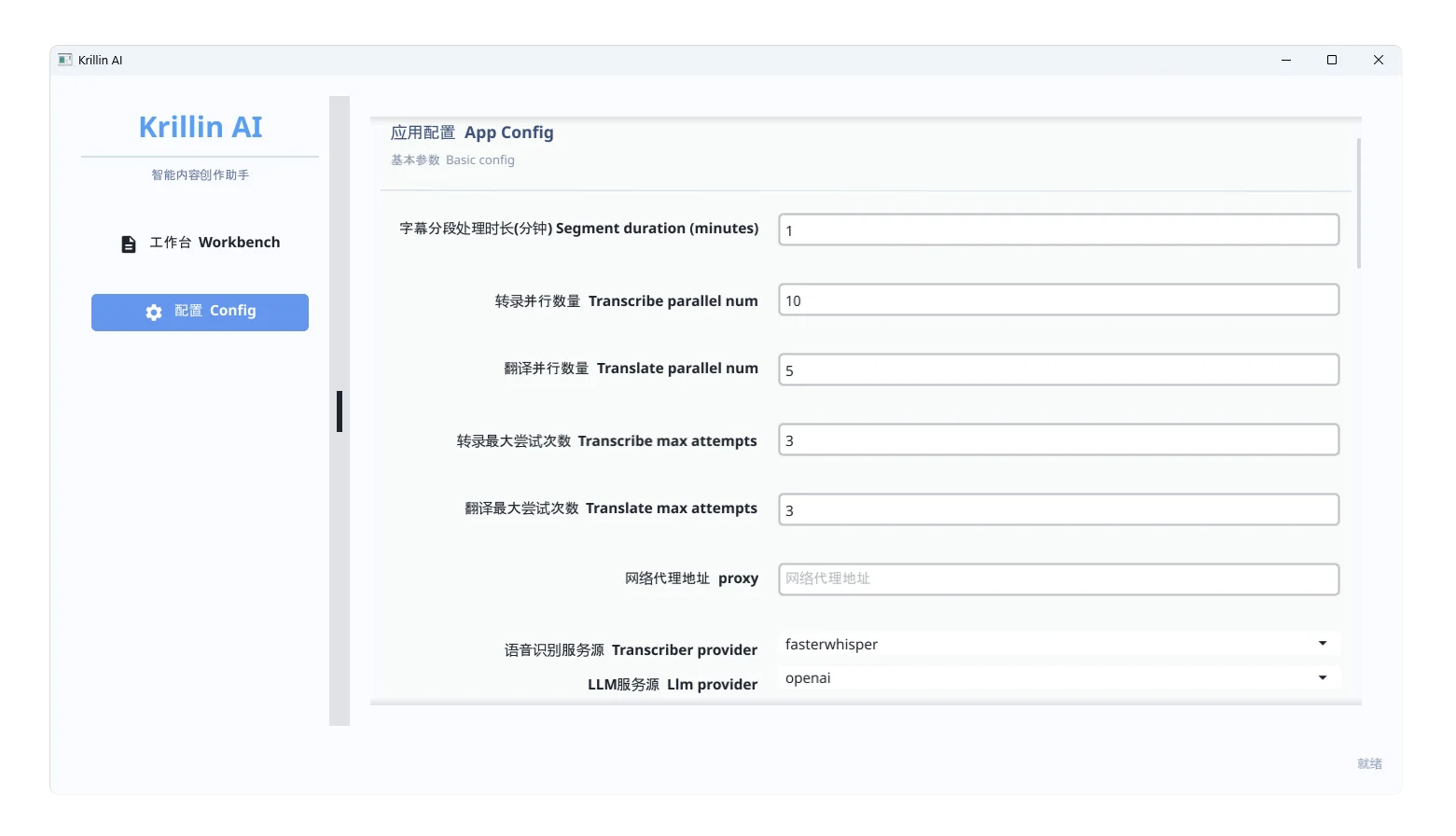
字幕分段处理时长
设置每段音频处理的时间长度(单位:分钟),例如设置为 2,就会将整个音频切成每段 2 分钟进行识别和翻译。
并行数量
控制同时处理的任务数量。视你的 CPU 或 GPU 性能决定,建议不要设置太高,避免卡顿或崩溃。
语音识别服务源
设置你使用的语音识别模型来源,推荐使用本地部署的 Whisper 模型(如 LM Studio 配置好后提供的服务地址)。
LLM 服务源
设置你用于翻译和润色文本的大语言模型服务地址。可以使用:
2. 服务器配置
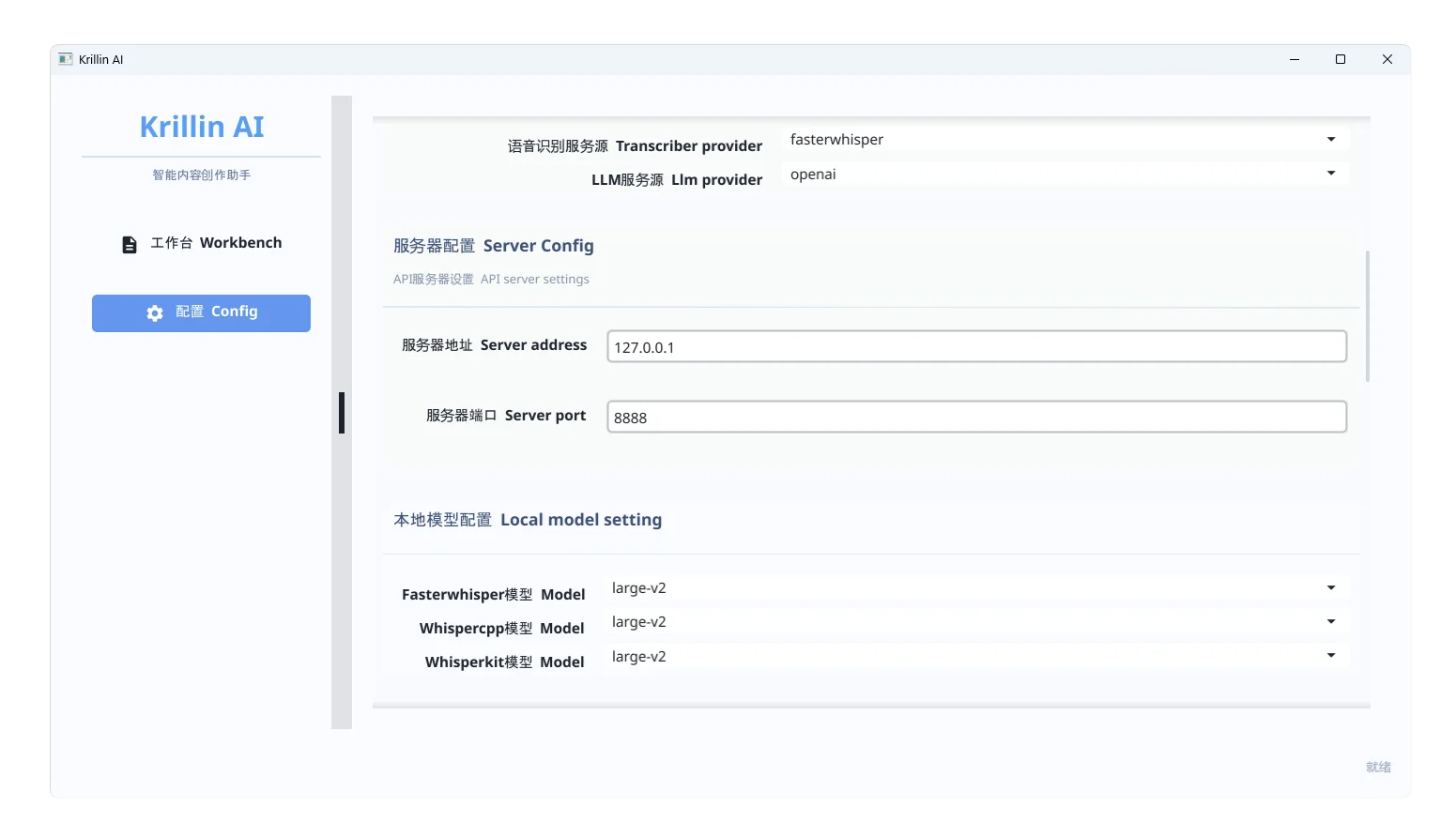
此部分保持默认即可,不需要修改,适用于大多数用户。
3. 本地模型配置(语音识别)
用于设置语音转文本所使用的本地模型,例如:
你可以将这个地址写入配置文件中对应位置,供语音识别模块调用。
4. OpenAI 模型配置(用于翻译)
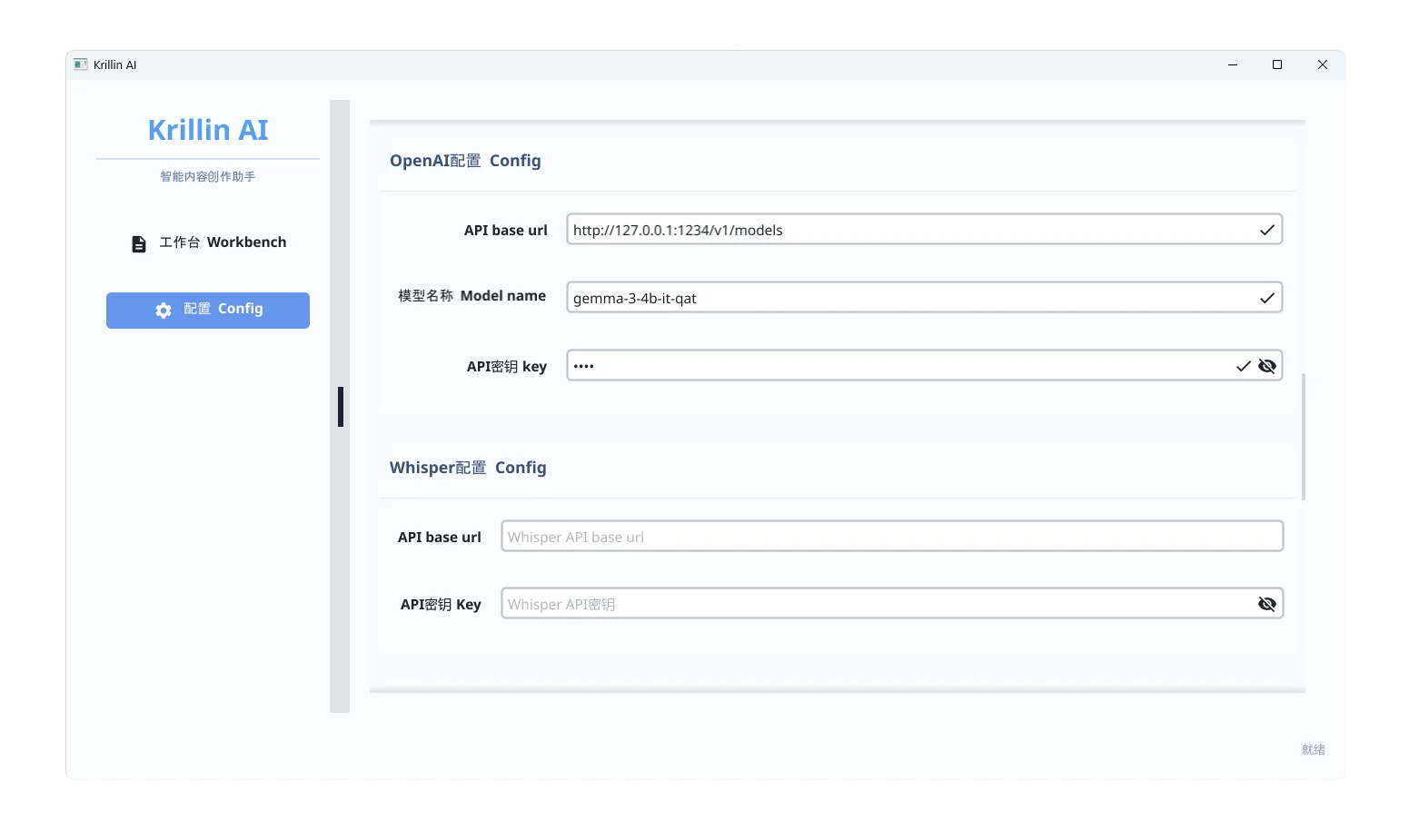
如果你使用 LM Studio 启动的本地模型(如 Gemma),请按以下步骤操作:
打开 LM Studio
选择本地模型:如 gemma-3-4b-it-qat
确保状态为 Status: Running
点击设置(Settings)→ 将访问地址设置为本机
配置参数如下:
API base url:
http://127.0.0.1:1234/v1/models(LM Studio 默认端口)
模型名称:
gemma-3-4b-it-qat(你加载的模型名称)
API 密钥:
输入任意内容(KrillinAI 只检查是否存在,不校验真实性)
保存配置即可。
5. 使用流程说明
输入方式
字幕设置
根据提示选择字幕语言、生成方式、分段长度等
推荐开启自动对齐、自动分段功能,提升准确率
配音设置
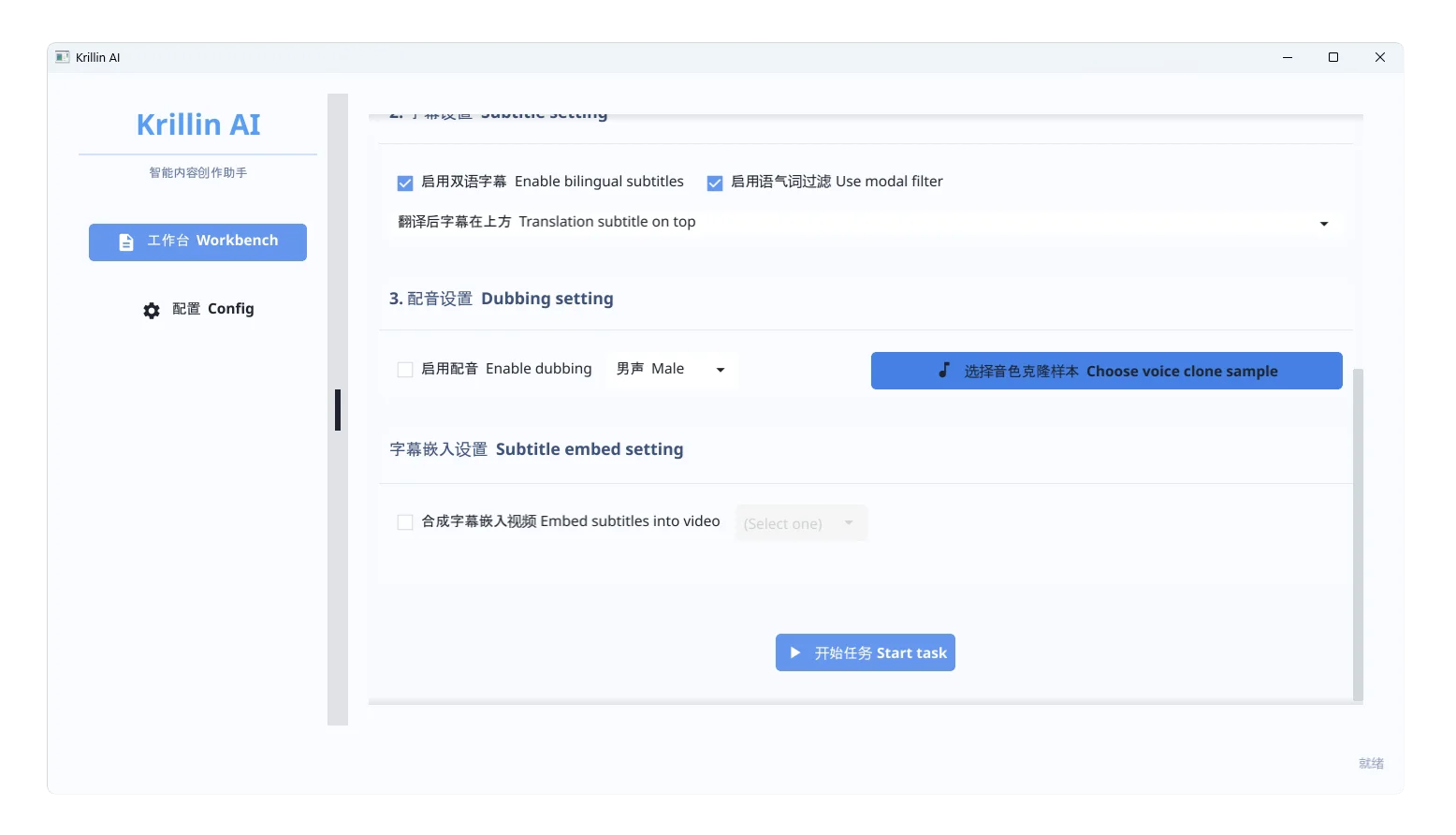
字幕嵌入设置
- KrillinAI_1.1.5_Desktop_Windows
- KrillinAI_1.1.5_Windows
- KrillinAI_1.1.5_macOS_arm64
- KrillinAI_1.1.5_Desktop_macOS_arm64
- KrillinAI_1.1.5_Desktop_macOS_amd64
百度网盘: KrillinAI 提取码: uzxq
国外网盘: KrillinAI