FramePack 是一个用于视频生成的下一帧预测神经网络框架,它基于深度学习技术,能够渐进式地生成视频。这个项目的核心目标是通过对输入帧的上下文进行压缩,使得生成的工作量不再受到视频长度的限制。它的特点是可以使用较小的 GPU 资源(例如笔记本电脑的 GPU)来处理大量的视频帧,甚至可以在像 RTX 30XX 系列这样的显卡上运行大型模型。
https://github.com/lllyasviel/FramePack/tree/windows
主要功能与特点
下一帧预测:
FramePack 采用了下一帧预测的方式,生成视频时逐步预测每一帧或每一段的图像,使得视频生成过程更加流畅,生成过程能够实时显示每一帧的变化。
恒定长度上下文:
该框架将输入的上下文压缩为固定长度,这样生成的视频不再受视频时长的影响,使得生成过程更加高效。
大规模模型支持:
FramePack 支持13B大小的模型,能够生成高质量的视频,且在笔记本电脑 GPU 上也能顺利运行。
视频扩散与图像扩散:
FramePack 提供了一种将视频生成与图像扩散相结合的方式,带来了更稳定且高质量的结果,同时也兼具图像生成的特点。
GPU优化:
该框架支持 NVIDIA RTX 30XX、40XX 和 50XX 系列显卡,并能够利用 fp16 和 bf16 精度进行加速,即便是配备较低内存的设备(例如6GB GPU)也可以运行。
可扩展性:
支持多种深度学习框架和模型,用户可以进行自定义和优化,适配自己的需求。
图形用户界面 (GUI):
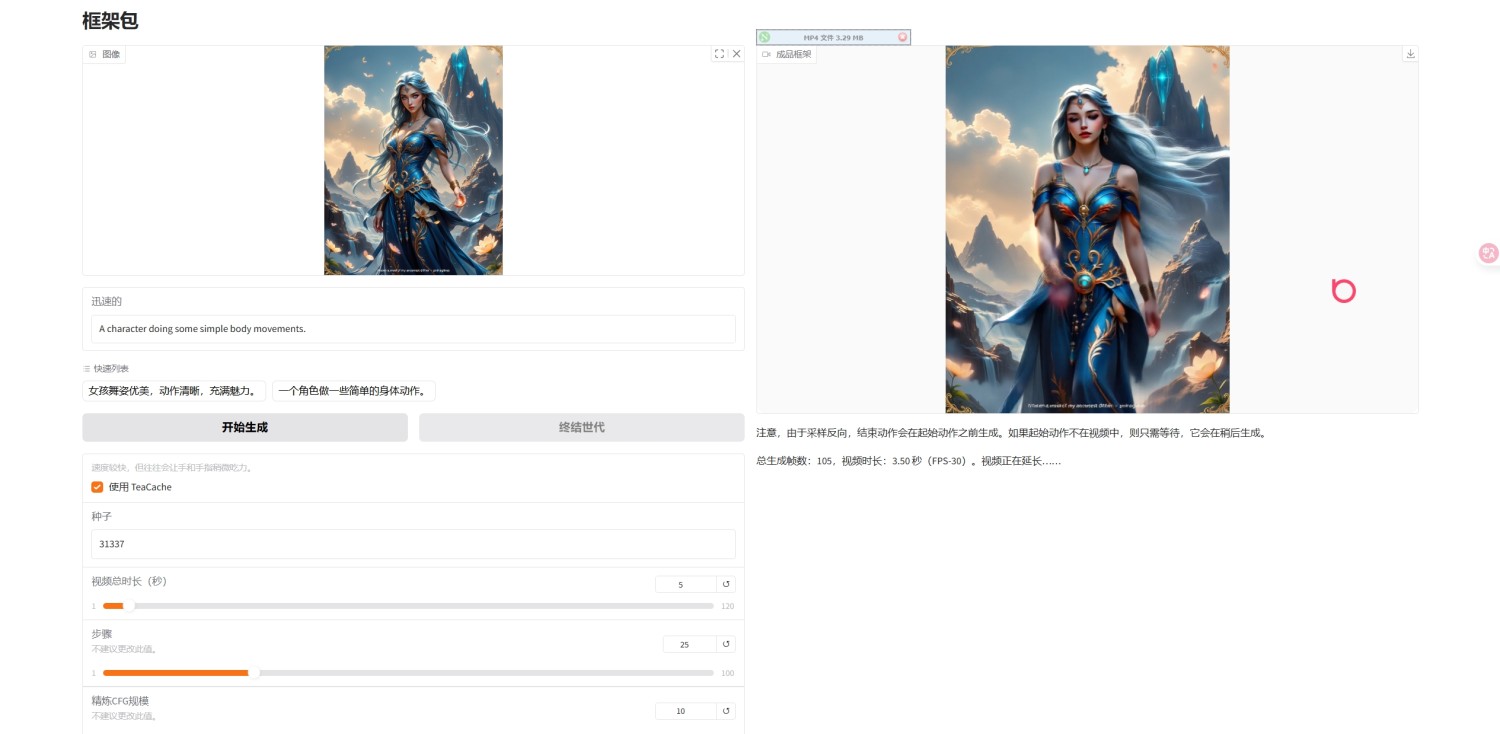
FramePack 提供了一个简单易用的 GUI,允许用户上传图像,设置提示词,并查看实时生成的视频帧。每一段视频都会显示进度条和潜在预览,使得用户可以直接看到生成效果。
安装与使用
Windows 安装:
- 下载一键包(包含 CUDA 12.6 和 Pytorch 2.6)。
- 解压后运行
update.bat 来更新环境。
- 使用
run.bat 启动程序。
- 模型文件会自动从 HuggingFace 下载,确保至少有 30GB 的存储空间。
Linux 安装:
生成视频:
用户只需上传一张图像并输入提示,FramePack 会自动开始逐帧或逐段生成视频。每个生成过程都会给出实时反馈,让用户看到每一段的效果。
注意事项
FramePack 提供了一个强大的平台,让视频生成过程变得更加高效和直观,适合那些希望探索下一代视频生成技术的研究人员和开发者。
百度网盘: FramePack 提取码: 8gws
官方:framepack_cu126_torch26.7z