WhisperDesktop 是一个基于 OpenAI 的开源语音识别模型 Whisper 构建的桌面应用程序。它旨在为用户提供一个简单易用的图形化界面(GUI),以便在本地计算机上运行 Whisper 模型进行语音转文字任务,而无需编写代码或依赖云端服务。WhisperDesktop 非常适合那些希望利用人工智能技术实现高精度语音转文字功能,但又不熟悉编程或命令行操作的用户。
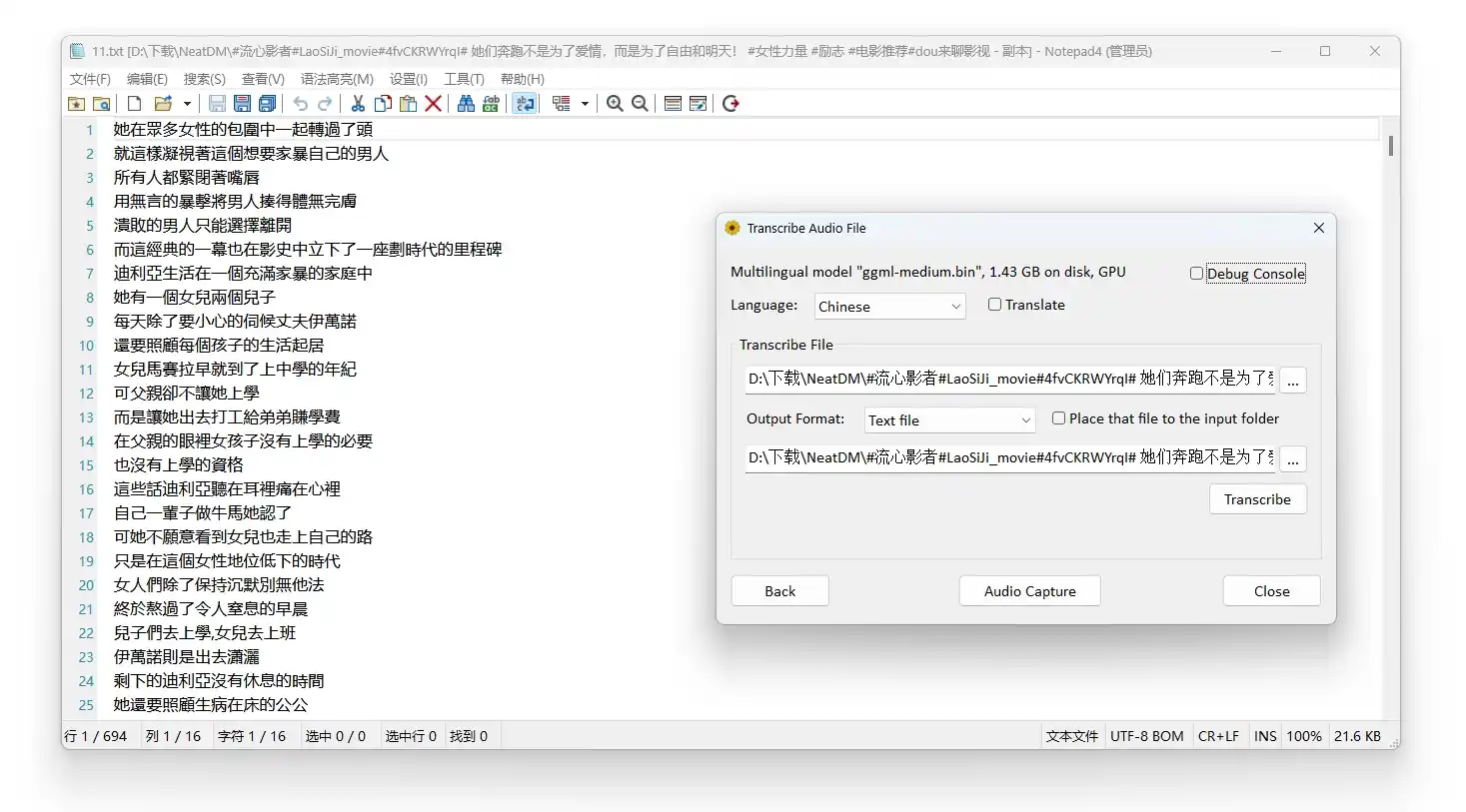
核心功能
- 语音转文字
- 支持将音频文件中的语音内容转换为文本。
- 提供高精度的语音识别能力,支持多种语言(包括中文、英文等)。
- 可处理长音频文件,适合会议记录、播客制作、字幕生成等场景。
- 多语言支持
- 基于 Whisper 模型,支持超过 90 种语言的语音识别。
- 能够自动检测音频的语言并生成对应的文本。
- 离线运行
- 所有语音识别任务均在本地完成,无需连接互联网。
- 保护隐私,避免敏感音频数据上传到云端。
- 批量处理
- 时间轴生成
- 自动生成每段语音的时间戳,便于制作字幕或逐句分析。
- 跨平台支持
- 支持 Windows、macOS 和 Linux 系统。
- 灵活导出
- 支持将结果导出为多种格式(如 TXT、SRT、VTT 等),方便后续编辑或使用。
特点与优势
- 用户友好 :
- 提供直观的图形化界面,无需编程知识即可完成复杂的语音转文字任务。
- 高性能 :
- 利用 Whisper 模型的强大能力,提供高质量的语音识别效果。
- 隐私保护 :
- 所有处理均在本地完成,确保音频数据的安全性和隐私性。
- 开源免费 :
- 灵活性 :
- 支持多种音频格式(如 MP3、WAV、FLAC 等)作为输入文件。
- 用户可以根据需求选择不同的 Whisper 模型(如小型、中型或大型模型)。WhisperDesktop 是一个基于微软 OpenAI Whisper 模型的音频转文本工具。它可以将音频或视频文件转换成 TXT 文本、SRT 字幕和 VTT 字幕。
关于长视频听译存在字幕重复的问题:
- WhisperDesktop
- Whisper_last_text_repeated_workaround(补丁文件)
- model
百度网盘: WhisperDesktop 提取码: h39a
阿里网盘: WhisperDesktop
文本输出循环/重复(直到结束)bug解决方法
https://github.com/Const-me/Whisper/issues/26
模型文件
https://huggingface.co/ggerganov/whisper.cpp/tree/main